
RAG Movie Plots: Understanding Narrative Structure Before Building RAG Systems
Introduction
When building Retrieval-Augmented Generation (RAG) systems, it is tempting to focus immediately on embeddings, chunk sizes, vector databases and prompt design. However, segmentation and retrieval behavior are not independent engineering choices. They are constrained by the structure of the data itself.
This article explores the structural characteristics of the Wikipedia Movie Plots dataset and examines how these properties influence practical design decisions in text segmentation and retrieval pipelines.
Instead of seeing preprocessing as a purely mechanical step, the aim here is to understand how narrative text behaves at scale, including its length, its consistency, how well metadata aligns with content and how these characteristics influence downstream NLP workflows.
This work is part of the broader RAG Movie Plots project, which focuses on building observable and inspectable RAG systems grounded in empirical analysis rather than black-box experimentation. The architectural foundations of this project were introduced previously in Designing a Modular RAG System. Here, we focus on the structural properties of the dataset that constrain those architectural decisions.
Why Dataset Structure Matters for RAG
Chunking is not something you tune in isolation. What you can do is largely constrained by the structure of the dataset itself.
Movie plots exhibit substantial variability. Some consist of just a few sentences, while others stretch across tens of thousands of characters. Some are written as a single uninterrupted paragraph, while others include explicit paragraph separations or line breaks. This heterogeneity has direct implications for how the text can be segmented without compromising semantic continuity.
Before choosing a text splitter or defining chunk overlap, it is essential to understand:
- How long the texts are
- How they are formatted
- Whether narratives repeat across entries
- Whether metadata fields are reliable
Inspecting structure first reduces guesswork and leads to segmentation strategies that reflect the behavior of the data instead of arbitrary heuristics.
Metadata Reliability and Hidden Inconsistencies
Before examining the narrative text itself, it is important to understand how metadata behaves across the dataset.
A first inspection reveals that fields such as Genre, Cast and Director include a considerable number of placeholder entries like “unknown” or “null”. More importantly, some placeholder-like values turn out to be legitimate entries depending on context. For example, the movie title Unknown is a valid film, even though the string “unknown” is often used as a missing-value marker elsewhere.
This makes one thing clear: placeholder handling needs to take the specific column and its context into account. Relying on simple string matching is not enough.
Further inspection shows more serious structural inconsistencies. In the Cast column, some rows contain values such as “Comedy” or “Drama“, clearly genre labels rather than actor names. Conversely, the Genre column sometimes includes production companies or studio names instead of genre descriptors.
These patterns strongly suggest partial column misalignment during dataset compilation. From a data engineering perspective, this is critical. If metadata is unreliable, retrieval strategies that depend on structured filters (e.g., “retrieve only action movies”) may behave unpredictably.
Cleaning is not merely superficial. It directly affects retrieval performance and, in turn, the overall behavior of the system.
Distributional Structure: Time and Origin
Looking at production distribution over time reveals a steady growth in the number of films across decades, with a strong concentration in more recent years.
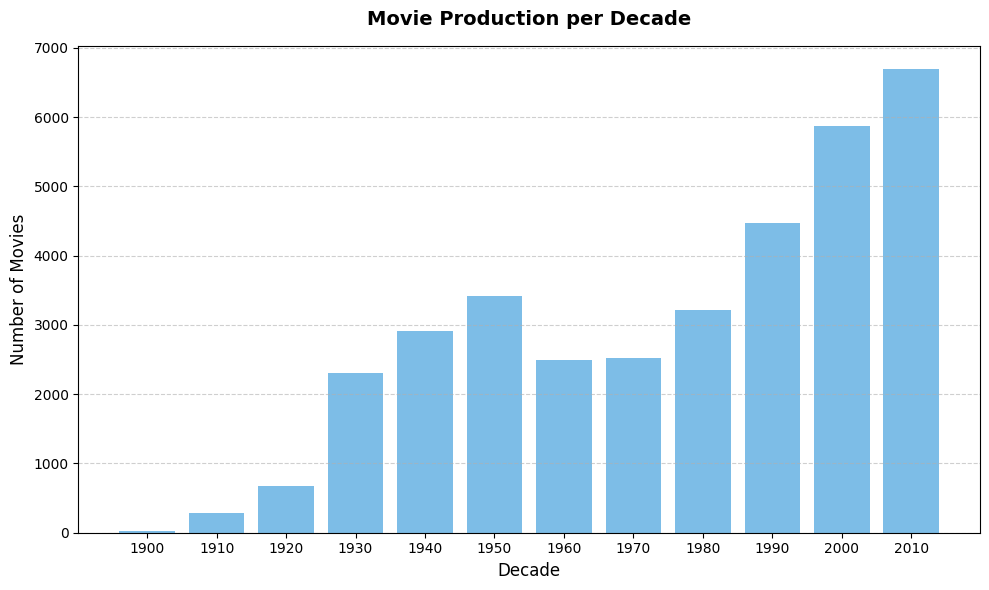
The strong concentration of movies in recent decades does not automatically create a bias in vector-based retrieval. However, because these entries are far more numerous, they occupy a larger portion of the corpus. In broad or ambiguous queries, this imbalance could increase the likelihood that retrieved results come from those periods. This is a hypothesis rather than a measured effect and it would require dedicated experiments to validate.
Geographically, the dataset is heavily concentrated in a small set of production regions, particularly American films.
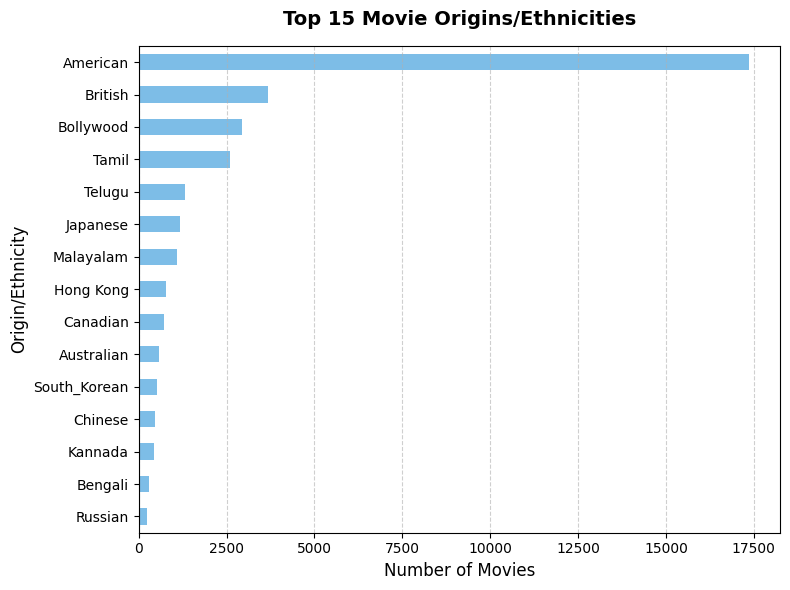
Although these plot summaries follow a relatively standardized encyclopedic style, the strong concentration in certain production regions means that many entries may describe similar cultural settings, recurring character types and genre-specific themes.
Because embeddings capture statistical regularities in language use, this distributional concentration can shape similarity structures across the corpus. It does not introduce an explicit bias, but it reflects the composition of the underlying dataset and may subtly influence how related narratives cluster.
Plot Length Variability: A Segmentation Constraint
The Plot field is the central textual component of this dataset and the main source of information used for retrieval. Its length distribution is highly skewed.
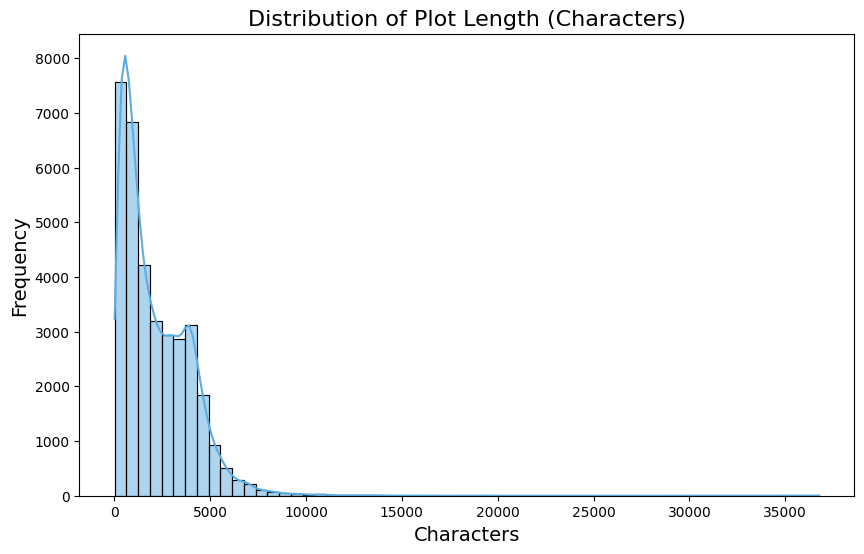
Most plots are relatively short, but a long tail extends to extremely long narrative summaries. The shortest plot in the dataset contains only a few characters, while the longest spans tens of thousands.
Given the wide variation in plot length, a single chunk size will inevitably represent a trade-off. A setting that preserves continuity in long texts may split shorter ones more than necessary, while a conservative size may fail to adequately structure longer narratives. The goal, therefore, is not to eliminate this trade-off, but to ground the chosen parameters in the observed characteristics of the dataset rather than adopt arbitrary defaults.
Literal Plot Duplication Across Records
Length variability is not the only structural pattern that emerges during inspection. Duplication also appears in multiple forms across the dataset. In some cases, distinct records share exactly the same plot summary while differing only in metadata such as release year, director, or country of origin.
The Mob Story example illustrates this pattern clearly: multiple entries contain identical plot text, including the same length and wording, yet appear as distinct records in the dataset. A similar phenomenon appears in some franchise-related entries, where the same descriptive text is attached to multiple titles.
When identical or near-identical descriptions are embedded, they generate vectors that occupy nearly the same region of the vector space. As a result, a similarity search may return multiple chunks that are technically relevant but add no new information.
This has direct implications for RAG pipelines. If duplication is not addressed, retrieval results may overrepresent repeated narratives and evaluation metrics may appear artificially strong simply because the system retrieves the same content in slightly different forms.
This has practical implications:
- Redundant storage in the vector database
- Repetitive top-k retrieval results
- Inflated evaluation metrics due to duplicated relevance
Understanding duplication is therefore not a minor cleanup task. It directly affects how retrieval behavior should be interpreted and how evaluation should be designed.
Title Repetition Across Decades
A related but distinct structural pattern emerges when examining title frequency. Several titles appear repeatedly across different release years, including The Three Musketeers, Cinderella and Treasure Island, among others.
Unlike literal duplication, these cases reflect remakes, adaptations and reinterpretations of the same underlying story. Each entry corresponds to a separate production, yet the narrative core often overlaps substantially.
From a retrieval standpoint, this creates both opportunity and trade-offs.
On one hand, repeated titles enable meaningful cross-temporal narrative linking. A similarity-based system can connect different adaptations of the same story, allowing retrieval to surface related works across decades.
On the other hand, this overlap increases the likelihood that top-k results include multiple versions of the same narrative when broader thematic coverage might be desired. In such cases, relevance does not guarantee diversity.
Again, structure matters. Whether repetition reflects editorial duplication or legitimate adaptation, it shapes the geometry of the embedding space and influences retrieval behavior in subtle ways.
What This Means for Text Segmentation
Taken together, these observations change how segmentation should be designed. Choosing chunk size and overlap is not just a matter of tuning parameters. Those decisions need to reflect how the data actually behaves.
In this dataset, plot lengths vary widely. Some entries are duplicated. Certain metadata fields are inconsistent. Categories are unevenly distributed. Each of these factors affects practical design choices:
- How large chunks should be
- How much overlap is necessary
- Whether metadata can reliably guide filtering
- How retrieval performance should be evaluated
If segmentation is defined without accounting for these structural properties, the system may end up reinforcing quirks of the dataset. For example, duplicated plots may inflate retrieval metrics, long narratives may be truncated and short summaries may be unnecessarily fragmented.
Series Context
In the previous article, Designing a Modular RAG System, the RAG Movie Plots project was introduced from an architectural perspective, separating ingestion and retrieval into explicit layers.
This article moves one level deeper. Instead of focusing on system structure, it examines the dataset itself, the raw material that ultimately determines segmentation behavior, embedding geometry and retrieval dynamics in practice.
Architecture decisions cannot be separated from the data they operate on. Without examining the dataset’s structure, optimization turns into trial and error. The goal here is to base the ingestion layer on empirical analysis, so that design choices reflect how the data actually behaves.
Part of the RAG Movie Plots Series:
- Designing a Modular RAG System
- Understanding Narrative Structure Before Building RAG Systems
- From Structural Analysis to Chunking Decisions (upcoming)
Conclusion
Understanding narrative datasets requires more than summary statistics and missing-value counts. Structural variability, metadata inconsistencies and duplication patterns directly affect how information can be segmented, retrieved and interpreted.
By establishing a structural perspective on the Wikipedia Movie Plots dataset, this analysis provides the empirical foundation for subsequent experiments in chunking strategies, retrieval design and evaluation within the RAG Movie Plots project.
In the next article, we move from structural inspection to controlled segmentation experiments, examining how specific text splitters behave under real structural constraints.
Project Repository
This analysis is part of the RAG Movie Plots project. The complete implementation including ingestion pipelines, chunking experiments, vector store configuration and retrieval logic is available on GitHub:
Further Reading
The following resources provide technical background relevant to the architectural and data considerations discussed in this article:

