
RAG Movie Plots: From Structural Analysis to Chunking Decisions
Introduction
Chunking is one of the most frequently tuned parameters in Retrieval-Augmented Generation (RAG) pipelines. Engineers often experiment with chunk size, overlap and separator hierarchies in search of improved retrieval performance.
However, segmentation strategies do not exist in isolation. The effectiveness of a chunking configuration depends heavily on the structural characteristics of the underlying dataset.
In the previous article, Understanding Narrative Structure Before Building RAG Systems, we examined several structural properties of the Wikipedia Movie Plots dataset (Kaggle), including formatting variability, metadata inconsistencies and narrative duplication. Those observations revealed that text segmentation decisions must reflect how the data actually behaves rather than relying on default configurations.
This article continues that investigation by translating those structural insights into concrete chunking decisions. Instead of selecting parameters arbitrarily, we derive them from the empirical characteristics of the corpus and examine how they influence the behavior of a recursive text splitter.
Structural Properties of the Dataset
Before defining a chunking strategy, it is important to understand how narrative text is structured in the dataset. Formatting features such as paragraphs and line breaks are often assumed to provide natural segmentation boundaries. However, their usefulness depends on how consistently they appear in the corpus.
To examine this aspect, we analyze three structural properties of the plot summaries:
- Document length (in characters)
- Paragraph structure
- Line structure
These metrics help determine whether segmentation strategies can rely on formatting boundaries or whether they must be guided primarily by size constraints.
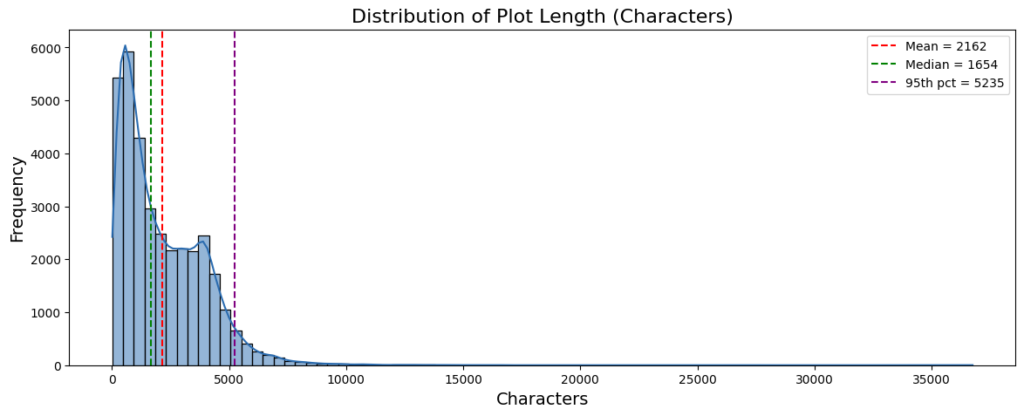
Plot Length Distribution
Movie plot summaries vary widely in length. Some entries contain only a few sentences, while others span several thousand characters.
Understanding this distribution is essential because chunk size determines how narratives are divided during ingestion. A chunk size that is too small may fragment longer narratives excessively, while a chunk size that is too large may fail to structure long documents effectively.
Paragraph Structure
Paragraph boundaries might appear to be natural segmentation points for text chunking. In practice, however, most Wikipedia movie plots are written as a single continuous block of text.
To quantify this property, we count the number of paragraphs in each plot by splitting normalized text on double newline characters. The resulting statistics reveal extremely limited variation in paragraph counts across the dataset:
- The median number of paragraphs is 1
- Even the 95th percentile remains 1
This means that the vast majority of plot summaries consist of a single paragraph. As a result, paragraph boundaries provide very little structural information for guiding text segmentation.
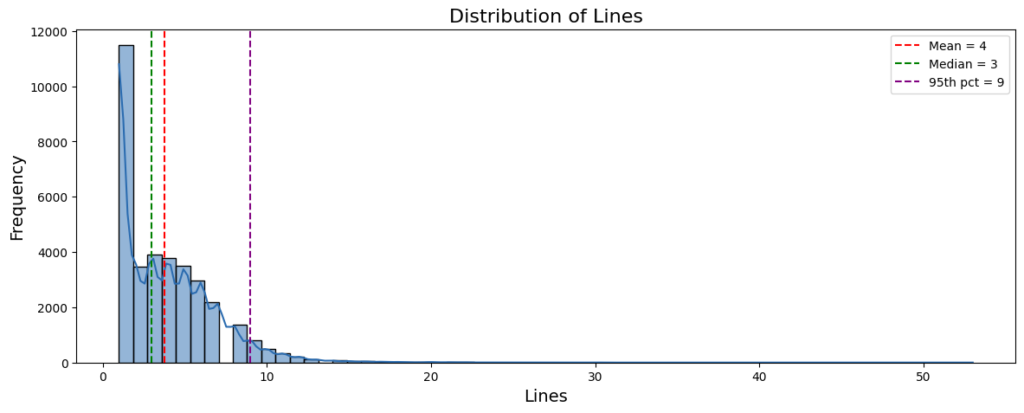
Line Structure
Line breaks sometimes separate narrative units, but their usage varies substantially across entries. Some plots contain several short lines, while others appear as a single continuous line of text. To examine how frequently line breaks occur, we compute the number of non-empty lines in each plot.
The resulting statistics reveal moderate variation:
- Median: 3 lines per plot
- Mean: ~3.8 lines
- Standard deviation: ~3.0 lines
- 95th percentile: 9 lines
These values indicate that most plots contain only a few line breaks, with half of the entries having three lines or fewer. However, the relatively large standard deviation suggests that line usage varies considerably across the dataset.
While many plots contain only a small number of lines, some entries exhibit much higher counts, reaching more than 50 lines in extreme cases. This long tail reflects inconsistent formatting practices across the corpus.
Although line breaks occur more frequently than paragraph boundaries, their presence does not necessarily correspond to meaningful segmentation points in the narrative.
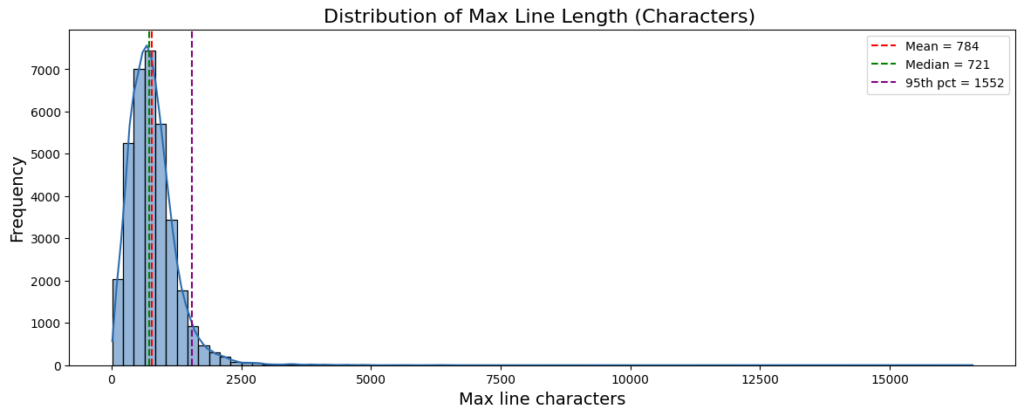
Maximum Line Length
The maximum line length provides a clearer picture of how newline-based segmentation behaves in practice. Across the dataset:
- Median maximum line length: ~721 characters
- Mean: ~784 characters
- 95th percentile: ~1552 characters
These results indicate that many plots contain very long lines spanning several hundred characters.
This has important implications for segmentation. When newline-based splitting is used, each line becomes a separator-delimited unit that the splitter attempts to preserve. If such lines are longer than the configured overlap window, the algorithm cannot reuse part of the previous segment, preventing overlap from being applied.
From Structural Evidence to Segmentation Strategy
The structural analysis presented previously revealed several constraints that directly influence text segmentation:
- Most plot summaries appear as single-paragraph narratives
- Line breaks exist but are inconsistently used
- Some lines are extremely long
- Narrative length varies widely across entries
These patterns make it difficult to rely on formatting features such as paragraphs or line breaks as primary segmentation boundaries. Instead, segmentation must be driven primarily by document length constraints while treating structural separators as optional opportunities to preserve natural textual boundaries.
This leads to a length-driven chunking strategy:
- Chunk size defines the primary segmentation constraint
- Structural separators are respected whenever possible
- Fallback segmentation ensures size limits are always satisfied
This approach ensures that segmentation remains robust even when formatting structure varies across the dataset.
Defining a Baseline Chunking Configuration
To operationalize this strategy, we adopt LangChain’s RecursiveCharacterTextSplitter. This splitter implements a hierarchical segmentation procedure. It first attempts to split text using larger structural separators and progressively falls back to smaller units when necessary to ensure the maximum chunk size is respected.
In practice, the algorithm attempts the following sequence:
- Paragraph boundaries (\n\n)
- Line breaks (\n)
- Spaces
- Individual characters
This hierarchy allows the splitter to preserve natural textual structure whenever possible while still guaranteeing that chunk size constraints are satisfied. The baseline configuration used in this analysis is:
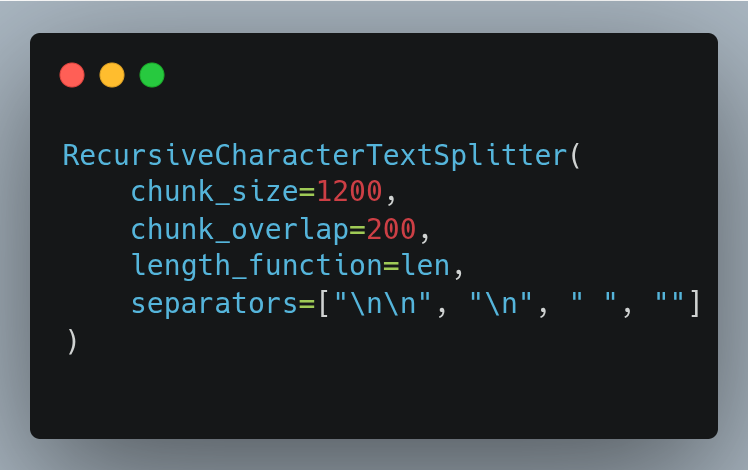
These parameters were selected based on the observed distribution of plot lengths across the dataset.
Choosing Chunk Size and Overlap
The choice of chunk size should reflect the empirical distribution of narrative lengths rather than arbitrary defaults. Across the dataset:
- Median plot length: ~ 1.6k characters
- Mean: ~ 2.1k characters
- Long tail extends beyond: ~ 5k characters
A chunk size of 1200 characters provides a practical balance between fragmentation and coverage. This value allows:
- Most short plots to remain within one or two chunks
- Longer narratives to be divided into manageable segments
Chunk overlap is configured as 200 characters. Overlap helps preserve local narrative continuity across chunk boundaries, particularly when references or transitions extend across multiple sentences.
However, it is important to interpret overlap correctly: in recursive splitting, overlap represents a maximum reuse window, not a guaranteed amount of repeated text. Whether overlap is actually applied depends on how the splitter interacts with structural boundaries in the text.
Robustness to Formatting Variability
The chosen configuration is designed to remain robust under the formatting inconsistencies observed in the dataset. Several structural patterns motivate this approach:
- Paragraph boundaries are rare
- Line breaks are inconsistently used
- Some lines span several hundred characters
Under these conditions, segmentation must prioritize size constraints while preserving natural boundaries opportunistically.
This design choice also avoids a known pitfall in newline-driven segmentation. As discussed in the companion analysis When separator=”\n” Silently Breaks Chunk Overlap in RAG Pipelines, aggressive reliance on newline separators can unintentionally suppress overlap behavior.
By maintaining a hierarchy of separators rather than privileging newline boundaries, the recursive splitter remains resilient to formatting variation across the corpus.
Inspecting Chunking Behavior
Before examining dataset-level statistics, it is useful to inspect how the splitter behaves on individual narratives. Examples extracted from the dataset illustrate how movie plots of different lengths are segmented into chunks.
In many cases, chunks are created without visible overlap. This occurs because the recursive splitter prioritizes structural separators when they provide valid split points that keep segments within the configured size constraint.
If a paragraph or line boundary appears before the chunk size limit is reached, the splitter can divide the text at that point without reusing part of the previous segment. Overlap is therefore introduced only when the algorithm must fall back to length-based splitting.
Notebook with some examples and chunk outputs:
Dataset-Wide Chunking Statistics
To understand how the splitter behaves across the entire dataset, we compute several statistics describing the chunking process. The analysis measures:
- Total chunks generated
- Chunk transitions between adjacent segments
- Number of overlaps detected
- Proportion of transitions containing overlap
Across the full corpus:
- 95,942 chunks were generated
- 61,056 chunk transitions were observed
- 7,598 overlaps were detected
This corresponds to an overlap ratio of roughly 12%. Despite the splitter being configured with a 200-character overlap, overlap is applied only in a minority of transitions.
This behavior reflects the recursive design of the splitter. When structural separators provide valid split points that keep segments within the configured size limit, the text can be divided directly at those boundaries, often without reusing content from the previous segment. However, if the separator-delimited unit is short enough to fit within the configured overlap window, part of the preceding segment may still be reused. When no suitable separator satisfies the size constraint, the splitter falls back to length-based splitting, which guarantees overlap.
What These Results Reveal About Recursive Chunking
The dataset-wide analysis highlights an important property of recursive text splitting. Overlap should not be interpreted as a fixed sliding window applied uniformly across the corpus. Instead, it represents a maximum allowable reuse window that becomes active only when segmentation requires it.
In practice, the behavior of the splitter emerges from the interaction between three elements:
- Chunk size constraints
- Separator hierarchy
- Structural properties of the text
When formatting structure provides suitable boundaries, segmentation follows those boundaries and chunks can often be created without reusing content from the previous segment. However, when structure is absent or inconsistent, the splitter must rely more heavily on length-based segmentation, which increases the likelihood that overlapping chunks will be produced.
This dynamic behavior explains why overlap is often observed less frequently than configuration parameters might suggest.
Series Context
This article is part of the RAG Movie Plots project, which explores how data structure influences the design of retrieval-augmented generation systems.
Part of the series:
- Designing a Modular RAG System
- Understanding Narrative Structure Before Building RAG Systems
- From Structural Analysis to Chunking Decisions (current article)
The series progresses from architectural design to data analysis and finally to segmentation strategies grounded in empirical evidence.
Conclusion
Chunking strategies are often treated as tunable parameters in RAG pipelines. In practice, their effectiveness depends strongly on the structural properties of the dataset. The analysis presented here shows that segmentation behavior emerges from the interaction between chunk size constraints, separator hierarchy and narrative structure.
Rather than applying a fixed sliding window, recursive text splitters dynamically adapt to available structural boundaries. As a result, overlap behavior is not uniform across the corpus and may occur less frequently than configuration parameters imply.
Understanding this interaction helps transform chunking from a heuristic configuration task into a data-driven design decision. By grounding segmentation strategies in empirical analysis, RAG systems become easier to reason about, easier to evaluate and ultimately more reliable.
Project Repository
This analysis is part of the RAG Movie Plots project.The complete implementation, including ingestion pipelines, chunking experiments, vector store configuration and retrieval logic, is available on GitHub:
Further Reading
The following resources provide technical background relevant to the architectural and data considerations discussed in this article:


